

IT at work wasn't happy when I responded to their "AI is now available!" announcement to remind them AI suggested glue as a pizza topping.

@ScottSoCal @ElleGray And Google's AI is still recommending it: https://www.theverge.com/2024/6/11/24176490/mm-delicious-glue

@jmccyoung @ScottSoCal @ElleGray
Again as funny this is not one of the dangerous ones, they are clearly dangerous and faulty.
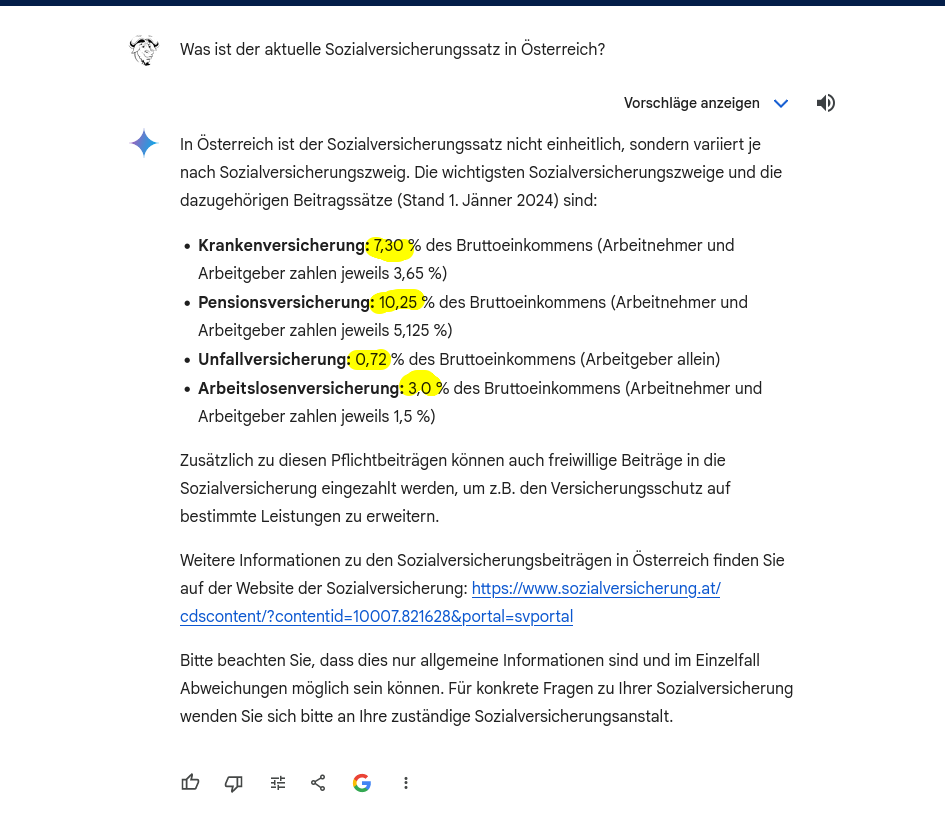
Gemini reporting in a convinced tone slightly wrong payroll tax rates (see attached screenshots, it claims they are current for this year even, and provides a kind of correct, but top-level URL)
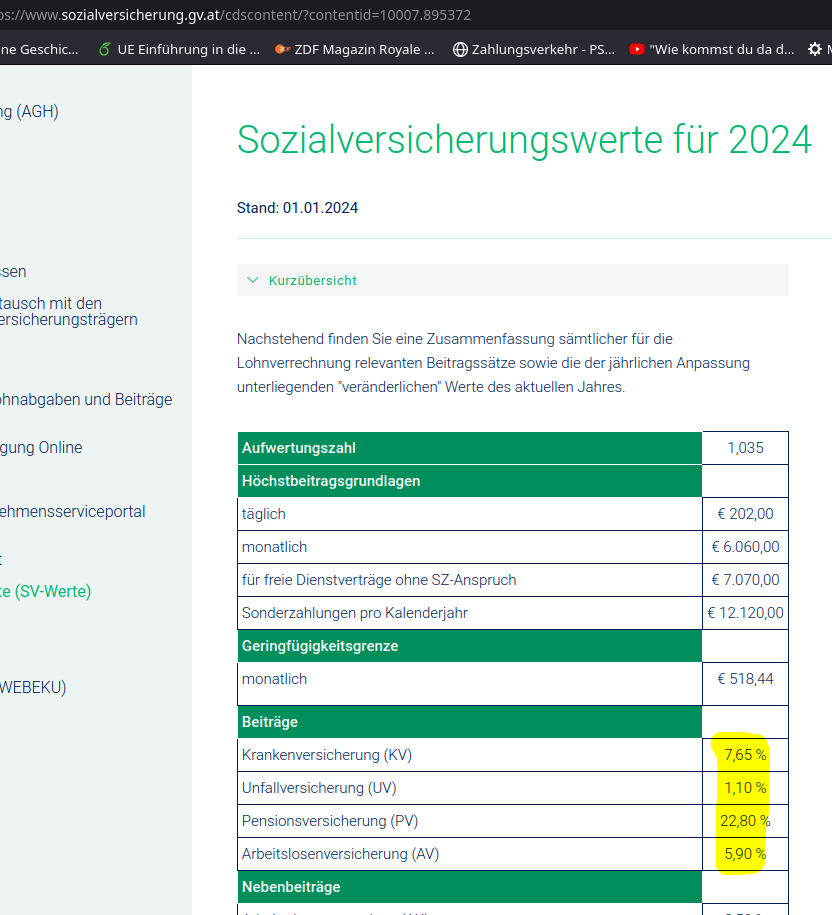
Notice the little whopper, the pension part: 10,25% is the actual employee part, according to a more detailed PDF here: https://www.sozialversicherung.at/cdscontent/load?contentid=10008.784719&version=1703166731 )
@jmccyoung @ScottSoCal @ElleGray
Note:
Gemini answered a German question about Austrian payroll taxes with a elegant, convincing answer, that contained seemingly all relevant information (it left out half a dozen of small ones in the <1% range out), with the wrong data (all the percentages are wrong, but most of them are off only by a small error).
And more believability to the big lie, it added a truly valid date when the update “social insurance thresholds, etc” usually happens.
@jmccyoung @ScottSoCal @ElleGray Plus it added a URL to the correct website of the Austrian social insurance, but only to the home page, so you have to find the correct info by clicking yourself to the info.
Perfect. If I wanted to do a presentation to present fake info about Austrian payroll taxes as true info, this is about how I'd go about it.
I guess Gemini AI Premium would add the colourful and extra manipulative graph slides that I might add to it.
@jmccyoung @ScottSoCal @ElleGray
Now let's analyse this in detail:
a) an Austrian tax advisor or payroll accounting specialist will probably spot the issues with the answer, especially if they read it and not only glance over it.
b) non-Austrian experts, or even Austrian business people, might accept it at face value. Sounds plausible, has references that are a little hard to check, let's run with it for the moment.
c) the general public will generally accept it as authoritative.
@jmccyoung @ScottSoCal @ElleGray
And BTW, I'm a well informed element in set B. Just currently evaluating the situation for a indepth discussion with our family's members of set A.
And the post showed up in my timeline while I have the social insurance data open in a tab, and Gemini open in a tab, thus the experiment.

{kind=link}
{kind=link}
@yacc143 @jmccyoung @ScottSoCal @ElleGray
This is the difference between searching on a search engine and receiving a top quoted result, including the source and a quote pulled from the source. If I don't get enough context surrounding the quote, I can click on the link and see the entire context. I can easily find locations, dates, etc. to gauge relevance. Nothing made-up, and I can use my own experience to know if the source is legitimate.
This is how humans used search engines effectively.
{kind=link}
@yacc143 @ScottSoCal @ElleGray I appreciated the more accurate term proposed here: https://undark.org/2023/04/06/chatgpt-isnt-hallucinating-its-bullshitting/ to replace "hallucination." The whole mechanism of LLMs is focused on plausibility; truth isn't a factor at all.
@jmccyoung @ScottSoCal @ElleGray
As I like to point out, truth is a hard to nail down concept. Yes, the easy questions sound easy, but even these can have surprising twists.
Now you might want to discuss sharks and batteries with some MAGA acolytes. The insights you'll gain might surprise you.
But without somehow a way for a computer to measure truth to guide the training of the network involved, it's unfair from us to expect them to be truthful.
@jmccyoung @ScottSoCal @ElleGray
And technically, it's not even “plausibility”, generally the training is measured against the test data set, which normally is a split of the training set, e.g. how similar the generated text is to the test part of the corpus. So it's “similarity to the training data”. Which presently is assumed to be mostly human written text.
(But you might see how this can turn ugly when the Internet fills up with AI-generated bull shit.)
@jmccyoung @ScottSoCal @ElleGray
Yeah, there is no quick way to get rid of such cool stuff from the outputs of a LLM:
You can try to add to the prefix rules that are added to the prompts that are sent to the LLM. That's hit or miss.
You can try to manipulate the training set of the LLM. Now that's hit or miss, and the compile time for a LLM (it's called training time) makes compiling complex C++ on a 64KB 8-bit box look like a great and speedy idea.

@ScottSoCal @ElleGray an AI would never pineapple on a pizza