
riddle me this: what's stopping AI scrapers from changing their user agent if they already don't respect robots.txt
stupid-ass arms race

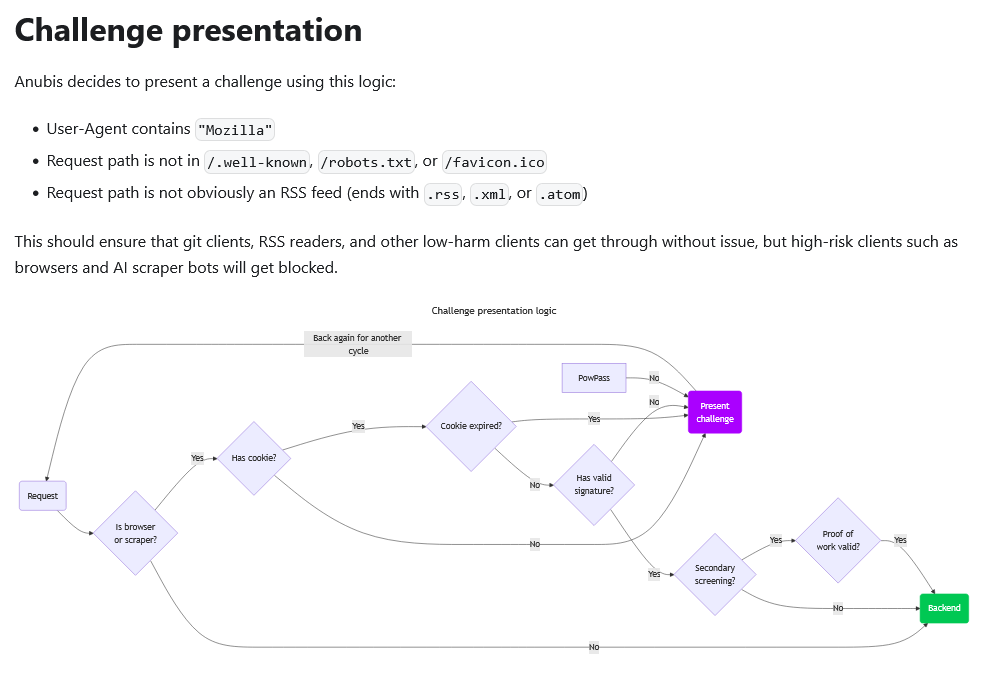{kind=link}
@mavica_again Nerd-sniped into searching GitHub for the answer
I think maybe it's a deliberate choice to not make it any more complicated than necessary for actual existing bots https://github.com/TecharoHQ/anubis/pull/78#issuecomment-2764334672
@madewokherd i get it but like. then what's the point
this was prompted by a forum post pointing out you can get rid of anubis (which they argue is harmful for getting in the way of javascript-free browsing) by just making your user-agent as wget's
@mavica_again The point is it doesn't take 5 minutes to load Bugzilla anymore. If that changes, then they escalate, I guess.
@madewokherd like i said, arms race
because it's less than trivial for ai scrapers to change their user agent
@mavica_again Apparently, they don't care that much (yet).
@mavica_again I bet AI companies could also trivially configure their scrapers to not DDoS the Internet, but apparently they don't care enough to do that either. It'd probably be less work for more payoff than participating in this particular arms race.

@madewokherd well, we'll see
at this point i'm just so tired.